

Sabe aquele momento em que você está nadando em um mar de dados e tudo o que queria era uma bóia que te dissesse: “Relaxa, tem um jeito de organizar isso aqui!”? Pois é. Se você trabalha com dados, com certeza já passou por isso. Os números estão ali, gritando por atenção, mas fazer sentido deles parece um daqueles desafios de montar móveis suecos sem manual.
A boa notícia? Esse tal “manual” existe – e se chama mineração de dados. Só que ao invés de um parafuso faltando, você vai encontrar insights escondidos que podem mudar completamente o rumo de um negócio, prever comportamentos ou até sugerir o próximo filme perfeito pra assistir num sábado à noite. E é aqui que a coisa fica séria (e divertida): mineração de dados não é só filtrar uma planilha ou rodar um algoritmo genérico. É entender o que esses dados querem te contar, usando técnicas, ferramentas e um tantinho de intuição treinada.
Bora minerar?
⛏️ Fundamentos e Conceitos Básicos de Mineração de Dados
Antes de sair aplicando algoritmo por aí igual receita de bolo do TikTok, vale a pena entender de onde vem essa tal de mineração de dados — e o que ela realmente significa.
📖 O que é mineração de dados?
Mineração de dados (ou data mining, no jargão dos gringos) é o processo de explorar grandes conjuntos de dados para descobrir padrões, correlações, tendências ou qualquer pepita de ouro que esteja escondida ali. É como escavar uma montanha de informações em busca de algo valioso — só que, no lugar de picareta, você usa matemática, estatística e machine learning.
A ideia central é transformar dados brutos em insights acionáveis. Coisas como:
- “Esse cliente provavelmente vai cancelar a assinatura no próximo mês.”
- “Se alguém comprou A e B, provavelmente também vai querer C.”
- “Usuários que viram esse produto também curtiram aquele outro ali.”
🧩 Componentes essenciais do processo
A mineração de dados costuma seguir um processo bem definido:
- Coleta e preparação dos dados
Dados precisam estar organizados, limpos e formatados para análise. Isso significa remover duplicações, lidar com valores ausentes e transformar dados categóricos em números (famosa codificação). - Seleção e transformação
Nem toda variável é útil. Nessa etapa, você seleciona os atributos mais relevantes e, se necessário, os transforma (normalização, PCA, one-hot encoding etc.). - Modelagem
Agora sim entram os algoritmos: regressão, árvores de decisão, clustering, redes neurais… A escolha depende do problema e do tipo de dado. - Avaliação
Você testa o modelo usando métricas como acurácia, precisão, recall, F1-score. Aqui é onde você percebe se minerou ouro ou só cavou buraco à toa. - Implantação
Por fim, se o modelo está bom, ele vai para produção. Pode ser usado para prever vendas, personalizar marketing, sugerir filmes… enfim, virar solução prática.
🤔 Mas isso é diferente de BI?
Sim, meu caro Watson! Business Intelligence (BI) é mais sobre responder perguntas conhecidas — tipo: “Quantos clientes compraram em março?”. Já a mineração de dados busca perguntas que você nem sabia que precisava fazer. É investigativo, preditivo e até um pouco filosófico.
Exemplo de aplicação prática
Imagina que você trabalha com e-commerce. Você tem milhões de registros de compras. Com mineração de dados, dá pra descobrir que:
- Clientes que compram fralda também compram cerveja (sim, isso já rolou de verdade).
- Se alguém abandonou o carrinho e clicou num e-mail específico, tem 60% de chance de finalizar a compra se for impactado com uma notificação push em até 2 horas.
🛠️ Técnicas de Mineração de Dados

Se o processo de mineração de dados fosse um jogo de RPG, as técnicas seriam suas habilidades especiais. Cada uma serve para um tipo de missão. Algumas preveem o futuro, outras agrupam comportamentos, e outras ainda só querem entender o que está acontecendo ali.
📊 Classificação (Classification)
A ideia aqui é simples: o algoritmo aprende com dados rotulados (ex.: clientes que compraram vs clientes que não compraram) e depois tenta prever a qual classe um novo dado pertence.
Exemplo:
Digamos que você queira prever se um cliente vai clicar num anúncio. Você treina seu modelo com dados históricos (idade, histórico de cliques, região, etc.) e o modelo vai dizer: “Este aqui tem 83% de chance de clicar”.
Algoritmos populares:
- Árvore de decisão
- Regressão logística
- Redes neurais
- k-NN (k-nearest neighbours)
🔁 Regressão
Aqui o modelo prevê valores contínuos. Ao invés de dizer “vai comprar ou não”, ele diz “provavelmente vai gastar R$ 179,22”.
Exemplo:
Prever a receita de vendas de um produto com base em promoções, época do ano e dados demográficos.
Modelos comuns:
- Regressão linear
- Ridge/Lasso
- Regressão com redes neurais (sim, dá pra fazer!)
🧩 Associação (Association Rule Learning)
Lembra da fralda com cerveja? Essa técnica identifica regras do tipo “se isso, então aquilo”.
Exemplo:
Na farmácia online, você percebe que quem compra vitamina D também compra colágeno. Aí o sistema já sugere o combo quando alguém coloca um deles no carrinho.
Algoritmo clássico: Apriori
🌐 Agrupamento (Clustering)
Aqui o objetivo é encontrar grupos semelhantes sem rótulo pré-definido. É a base de segmentação de clientes.
Exemplo:
Você quer entender quais perfis de usuários visitam seu site. O algoritmo descobre que existem basicamente 4 tipos: os curiosos, os comparadores de preço, os compradores rápidos e os indecisos crônicos.
Algoritmos comuns:
- K-means
- DBSCAN
- Hierarchical Clustering
🔍 Detecção de Anomalias
Serve para encontrar aquilo que foge ao padrão. E sim, pode evitar dor de cabeça com fraude ou falhas de sistema.
Exemplo prático:
Transações com valores fora do comum, ou horários suspeitos de acesso em sistemas corporativos.
Ferramentas populares:
- Isolation Forest
- One-Class SVM
- Autoencoders
🧠 Redução de Dimensionalidade
Perfeito para quando você tem muitos atributos e quer simplificar o modelo sem perder informação.
Exemplo:
Imagina um dataset com 100 colunas (variáveis). Você quer reduzir isso para 10 componentes que ainda expliquem 95% da variabilidade.
Técnica clássica:
- PCA (Principal Component Analysis)
🧬 Séries Temporais (Time Series)
Não é exatamente uma técnica de mineração, mas aparece tanto em aplicações reais que merece menção.
Exemplo:
Previsão de vendas mês a mês, análise de variação de temperatura, fluxo de usuários ao longo da semana.
Modelos comuns:
- ARIMA
- Prophet (Facebook)
- LSTM (quando misturado com deep learning)
🧰 Quando usar cada uma?
| Objetivo | Técnica principal |
|---|---|
| Prever uma categoria | Classificação |
| Prever um número | Regressão |
| Descobrir padrões de consumo | Associação |
| Agrupar perfis similares | Clustering |
| Detectar comportamentos estranhos | Anomalias |
| Lidar com dados complexos | Redução de dimensionalidade |
| Analisar dados no tempo | Séries temporais |
🤖 Aprendizado de Máquina Aplicado à Mineração de Dados

Se mineração de dados fosse uma banda, o aprendizado de máquina seria o vocalista carismático. Ele é quem atrai a atenção, entrega os maiores hits e faz a galera gritar “isso é bruxaria tecnológica!”. Mas calma, tem ciência por trás de tudo.
📌 Mas o que é aprendizado de máquina?
É o campo da ciência da computação onde os algoritmos aprendem com dados. Em vez de programar todas as regras do jogo, você dá exemplos e deixa o sistema aprender sozinho como jogar.
Na mineração de dados, o machine learning é a alma do negócio. Ele permite que os sistemas:
- Classifiquem clientes como bons ou maus pagadores.
- Prevejam a chance de um cliente abandonar o serviço.
- Segmentem usuários com base no comportamento.
- Detectem fraudes ou padrões fora do comum.
⚖️ Aprendizado supervisionado vs. não supervisionado
Supervisionado
Aqui você treina o modelo com dados rotulados. Exemplo: “Este cliente cancelou o plano. Este aqui, não.” O modelo aprende a reconhecer os padrões que indicam cancelamento.
Algoritmos populares:
- Regressão logística
- Árvores de decisão
- Redes neurais
- SVM
Não supervisionado
Você não fornece rótulos. O modelo descobre sozinho as estruturas ocultas nos dados.
Aplicações:
- Segmentação de clientes
- Detecção de padrões incomuns
- Agrupamento de documentos ou imagens
Algoritmos populares:
- K-means
- DBSCAN
- PCA
🎯 Onde o ML brilha na mineração de dados?
| Tarefa | Exemplo prático | Algoritmo comum |
|---|
| Prever comportamento de cliente | Churn prediction | Regressão logística, Árvores |
| Classificar e-mails como spam | Filtros de spam | Naive Bayes, Redes neurais |
| Recomendação personalizada | Sugerir produtos baseados em histórico | Colaborativo + ML |
| Diagnóstico médico automatizado | Detectar doenças com base em sintomas | SVM, Redes neurais |
| Detecção de fraude | Identificar transações fora do padrão | Isolation Forest, Autoencoders |
🧠 Modelos que aprendem, melhoram e se adaptam
A grande vantagem do ML é que os modelos não só aprendem com os dados iniciais, mas também podem ser atualizados conforme novos dados surgem. É como treinar um funcionário que nunca para de melhorar.
🛠️ E o melhor? As ferramentas estão ao seu alcance
- Scikit-learn: perfeita para quem está começando e quer explorar muitos algoritmos de forma rápida.
- TensorFlow + Keras: ideal para modelos mais complexos, como redes neurais profundas.
- WEKA: ótima para explorar modelos visualmente e entender o comportamento dos algoritmos com poucos cliques.
📈 Modelos Lineares para Regressão e Classificação

Você não precisa de uma rede neural com mil camadas pra resolver tudo. Às vezes, um bom e velho modelo linear resolve o problema com classe e eficiência. E o melhor: em segundos.
🧮 Regressão Linear
Vamos começar com o clássico dos clássicos. A regressão linear tenta ajustar uma reta que explique a relação entre uma variável dependente (resposta) e uma ou mais variáveis independentes (explicativas).
Fórmula da regressão simples:
y = β0 + β1.x + ε
🔍 Componentes da fórmula:
y: é a variável dependente — ou seja, aquilo que você está tentando prever ou explicar.
x: é a variável independente — a variável usada para prever y.
β0: é o intercepto, também chamado de constante. É o valor de y quando x = 0.
β1: é o coeficiente angular ou inclinação da reta. Ele indica quanto y muda quando x aumenta em uma unidade.
ε: é o erro ou termo residual, que representa a parte de y que não é explicada por x. Ele capta a aleatoriedade ou fatores não observados.
🎧 Cenário:
Imagina que o Spotify quer prever quanto tempo você vai ouvir uma música (em segundos), baseado na energia da música — uma métrica que vai de 0 a 1 e representa o quão animada ou intensa ela é (batida, ritmo, etc).
🔢 A fórmula:
A regressão ficaria assim:
tempo_de_escuta = β0 + β1 . energia + ε
🧪 Exemplo com dados fictícios:
| Música | Energia (x) | Tempo de escuta (y, em segundos) |
|---|---|---|
| Lofi Chill | 0.2 | 180 |
| Pop Leve | 0.5 | 210 |
| Eletrônica Pesada | 0.9 | 300 |
| Trap Energético | 0.8 | 270 |
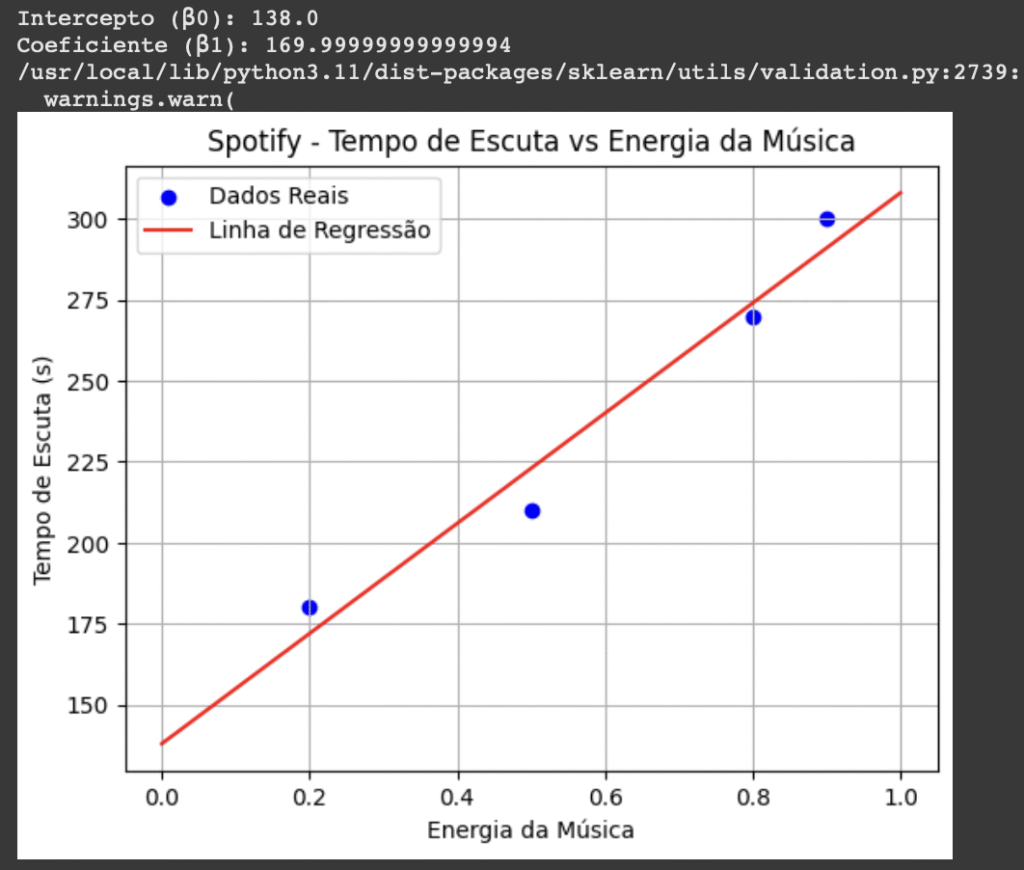
O modelo aprende com esses dados e descobre que:
- β0 = 150
- β1 = 150
Então, a fórmula vira:
tempo_de_escuta = 150+150⋅energia + ε
🔍 Interpretação:
- O tempo base de escuta é 150 segundos, mesmo pra músicas bem calmas.
- A cada 0.1 ponto a mais de energia, o usuário tende a ouvir 15 segundos a mais.
- O erro ε cobre variações aleatórias — tipo se você pulou a música porque alguém te chamou no WhatsApp.
🧠 Como isso ajuda o Spotify?
O Spotify pode usar esse modelo pra:
- Recomendar mais músicas com energia parecida com as que você tende a ouvir até o final.
- Evitar sugerir músicas que você costuma pular porque têm energia baixa demais pra sua vibe.
Exemplo de regressão linear com Python, usando pandas, matplotlib e scikit-learn, o código foi rodado no Google Colab
🧠 O que esse código faz:
- Cria um dataframe com os dados.
- Treina um modelo de regressão linear simples.
- Mostra os valores de β0β0 (intercepto) e β1β1 (coeficiente).
- Gera uma linha de previsão com base nos valores de energia.
- Plota o gráfico com os dados reais e a linha da regressão.
🧪 Regressão Logística
Apesar do nome, a regressão logística é usada para classificação, e não para prever números contínuos.
Ela tenta estimar a probabilidade de um evento acontecer — por exemplo, a chance de um cliente cancelar a assinatura.
Função logística:
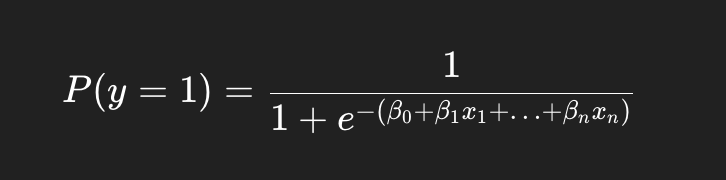
Mas como isso afeta o Spotify ?
Vamos criar um conjunto simples inspirado nos dados da Spotify Web API.
📊 Dados fictícios
| Música | Danceability | Energy | Popular (Hit?) |
|---|---|---|---|
| Song A | 0.80 | 0.85 | 1 |
| Song B | 0.60 | 0.50 | 0 |
| Song C | 0.90 | 0.95 | 1 |
| Song D | 0.40 | 0.30 | 0 |
| Song E | 0.70 | 0.75 | 1 |
| Song F | 0.30 | 0.20 | 0 |
| Song G | 0.85 | 0.80 | 1 |
| Song H | 0.50 | 0.45 | 0 |
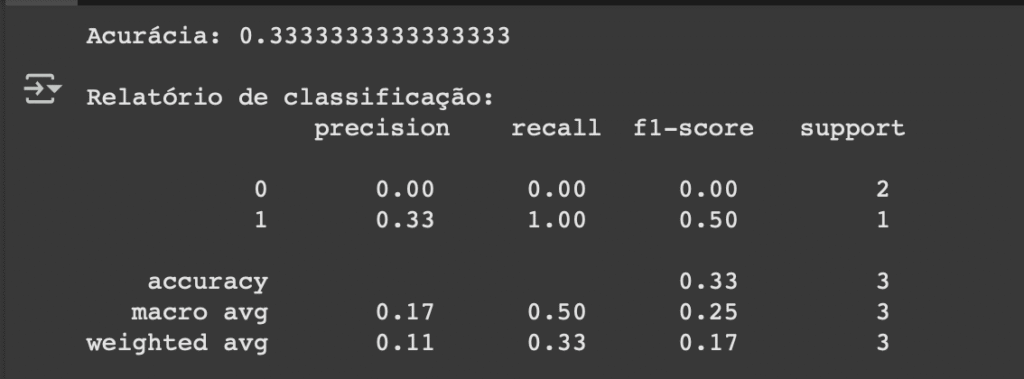
🌳 Comparando com Árvores de Decisão
Modelos lineares são rápidos, simples e interpretáveis. Mas não são bons com dados não lineares ou muito complexos. Aqui entram as árvores de decisão.
Árvores de decisão funcionam como aquele colega super organizado que sempre quer tomar decisões baseadas em perguntas simples e diretas.
“O cliente tem mais de 3 compras no último mês?”
Se sim → “Ele usou cupom?”
Se não → “Então talvez ele não esteja tão engajado.”
Exemplo prático:
Prever aprovação de crédito com base em idade, renda e histórico de pagamento. A árvore vai criar uma sequência de perguntas até chegar a um “sim” ou “não”.
Vantagens:
- Fácil de interpretar
- Suporta variáveis categóricas
- Funciona bem com dados mistos
Exemplo:
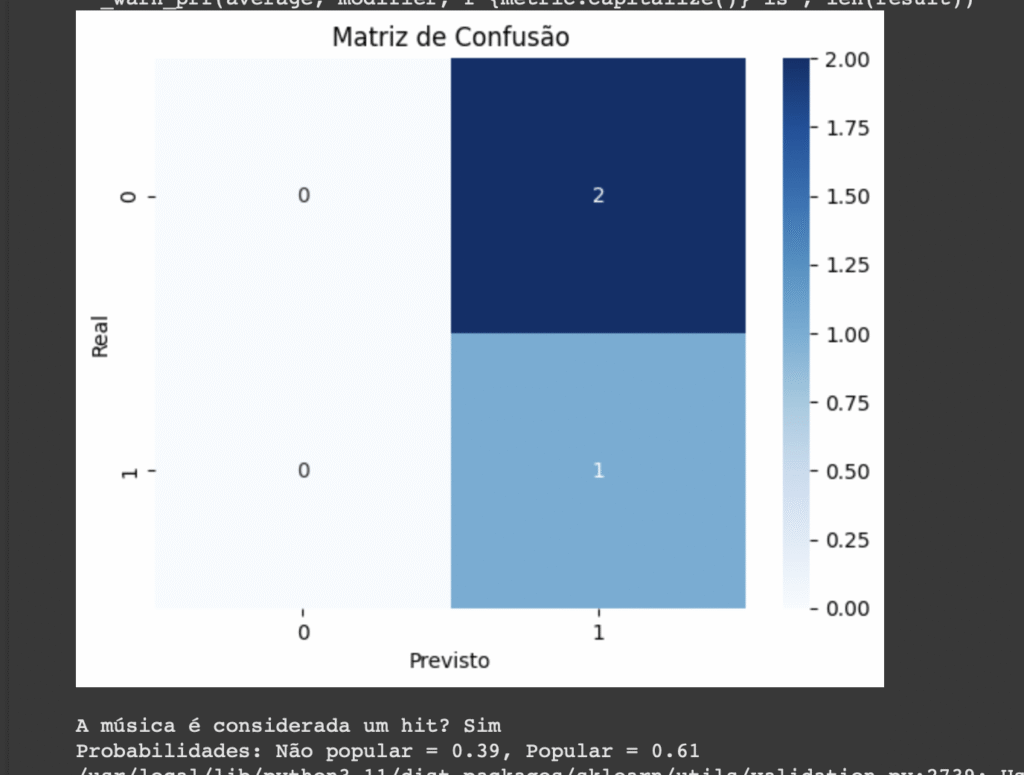
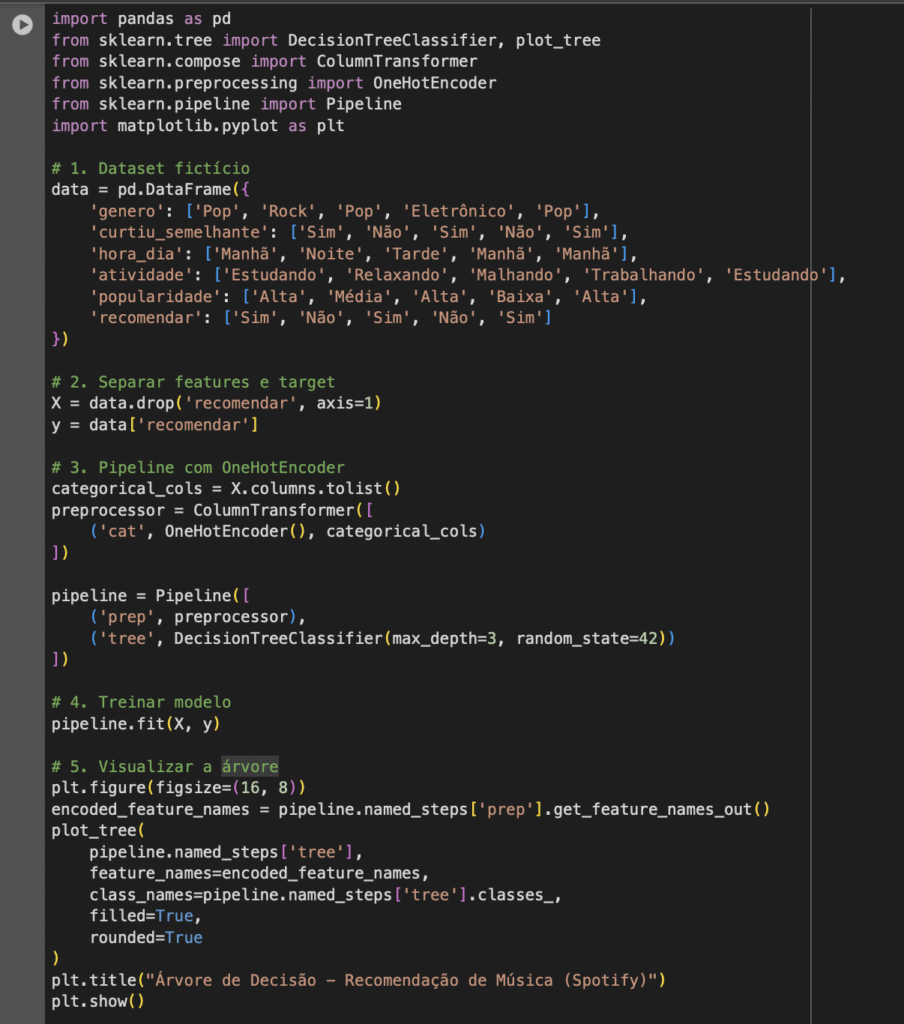
Imagine que o Spotify quer decidir se recomenda ou não uma nova música para um usuário com base em alguns critérios.
Para cada usuário, o sistema tem informações como:
- Gênero musical favorito (Pop, Rock, Eletrônico, etc.)
- Se o usuário curtiu músicas semelhantes antes (Sim/Não)
- Hora do dia (Manhã, Tarde, Noite)
- Tipo de atividade (Estudando, Trabalhando, Malhando, Relaxando)
- Popularidade da música (Alta, Média, Baixa)

Usuário:
- Gênero favorito: Pop
- Já curtiu músicas semelhantes: Sim
- Hora do dia: Manhã
- Atividade: Estudando
- Popularidade da música: Alta
Decisão pelo fluxo da árvore:
- Curtiu músicas semelhantes? → Sim
- Gênero favorito é Pop? → Sim
- Hora do dia é Manhã? → Sim
✅ Resultado: Recomendado
Também podemos usar a biblioteca sklearn, em Python.
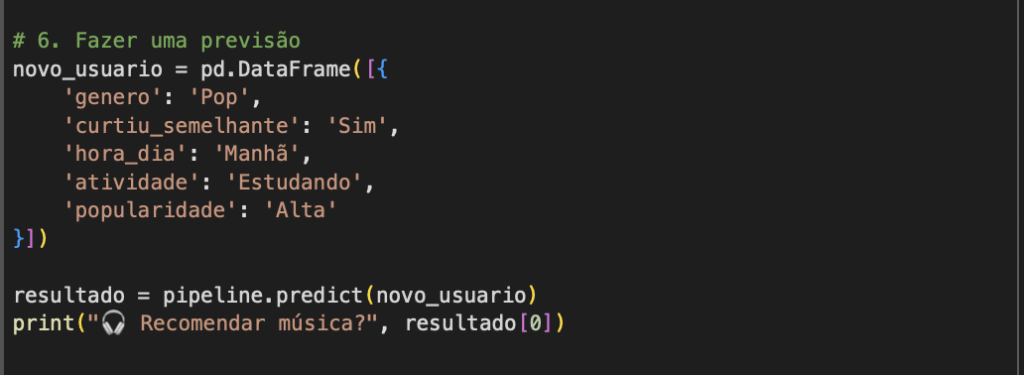
Resultado do código:

🆚 Mas afinal, quando usar o quê?
| Cenário | Melhor escolha |
|---|---|
| Dados com relação linear | Regressão Linear |
| Classificação binária simples | Regressão Logística |
| Dados com interações complexas | Árvore de Decisão |
| Precisa de interpretabilidade rápida | Regressão Linear/Logística |
| Classes bem definidas e discretas | Árvore de Decisão |
Mineração de dados não é só uma buzzword bonita pra colocar no LinkedIn — é uma habilidade estratégica pra transformar dados em decisões com impacto real. Se antes você via os dados como uma bagunça de números sem muito sentido, agora já sabe que por trás de cada clique, cada compra e cada abandono de carrinho, existe um padrão esperando pra ser descoberto.
Aqui vimos apenas alguns algoritmos que são usados na técnica de mineração mas existem muitos outros por ai…
Saiba mais:
Data Mining: Concepts and Techniques
Data Mining: Practical Machine Learning Tools and Techniques
Data Mining: o que é e para que serve

