
A explosão de dados e o aumento da complexidade dos sistemas modernos criaram um novo desafio para a engenharia de dados: como coletar, processar e transformar grandes volumes de dados de forma eficiente? Aqui entram os pipelines de dados, que são o coração de muitas soluções em engenharia de dados e análise.
O que é Pipeline de Dados?

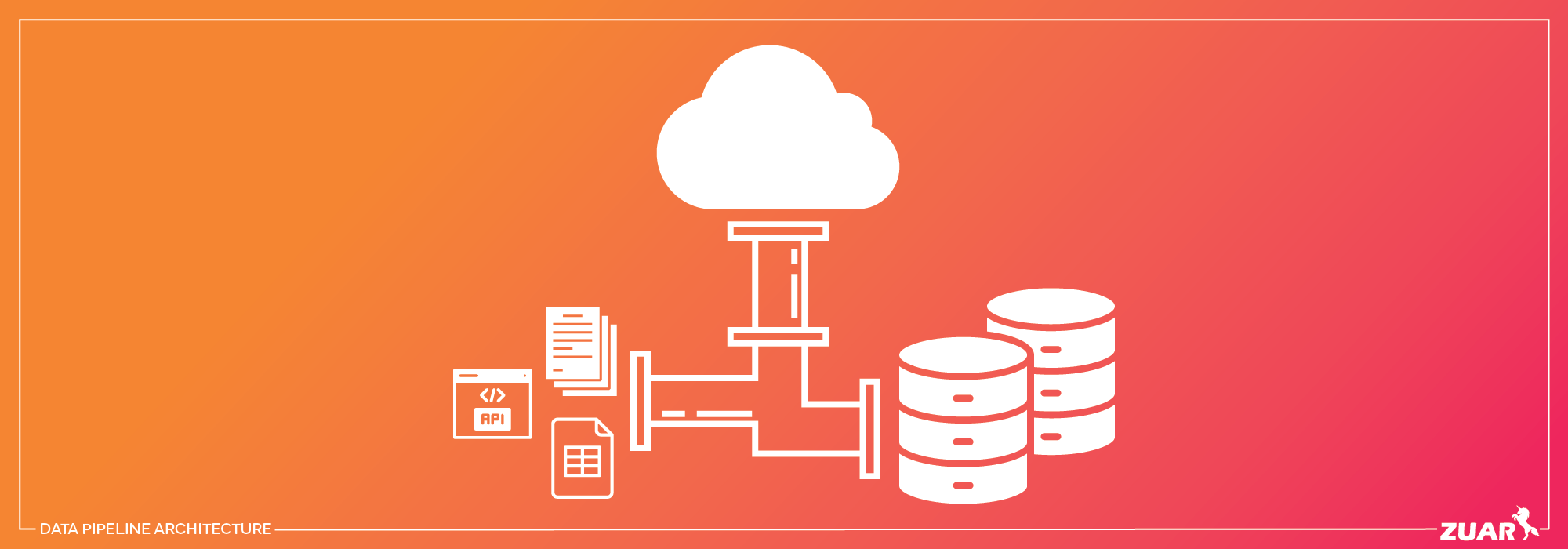
Um pipeline de dados é um conjunto de processos automatizados que movem os dados de um ponto a outro, realizando uma série de transformações e validações ao longo do caminho. Imagine um pipeline como uma fábrica onde os dados são os ingredientes crus que entram, e os insights ou relatórios são o produto final que sai.
O pipeline pode conectar diversas fontes de dados (como bancos de dados, APIs e arquivos), transformar essas informações e carregá-las para sistemas de destino (como data warehouses, dashboards ou aplicações de machine learning).
Suponha que uma empresa colete dados de vendas a partir de seu sistema de e-commerce, registros de clientes de um CRM e métricas de marketing de uma ferramenta como o Google Analytics. Um pipeline de dados pode automatizar a integração desses dados, limpá-los (removendo duplicatas, preenchendo valores nulos e etc), combiná-los e entregá-los a um sistema de análise para que a equipe possa tomar decisões estratégicas.
Componentes de um Pipeline de Dados

Os pipelines de dados são formados por diferentes componentes, cada um desempenhando um papel essencial para o fluxo e transformação dos dados:
Ingestão de Dados: O primeiro passo em um pipeline é a coleta de dados. Isso pode ser feito em batch(processamento em lotes) ou em streaming (dados em tempo real). Ferramentas populares para ingestão incluem Apache Kafka e AWS Kinesis.
Armazenamento Temporário: Os dados coletados geralmente são armazenados temporariamente em um data lake ou em uma área de preparação, como Amazon S3 ou Google Cloud Storage, para posterior processamento.
Transformação de Dados: Nesta fase, os dados passam por processos de limpeza, padronização e enriquecimento. Ferramentas como Apache Spark e Pentaho são comuns nesta etapa, permitindo realizar transformações escaláveis.
Orquestração: Um pipeline precisa de uma ferramenta que coordene todas as etapas do processo, garantindo que as tarefas sejam executadas na ordem certa e que erros sejam tratados de forma adequada. Apache Airflow e Prefect são opções populares para orquestração.
Carga e Entrega: A última etapa envolve carregar os dados transformados para um destino final, que pode ser um data warehouse, como BigQuery ou Snowflake, ou um sistema de visualização, como Tableau ou Power BI.
Pipeline de Dados X ETL
O termo ETL (Extract, Transform, Load) é amplamente conhecido, mas será que ele é o mesmo que um pipeline de dados?
Não exatamente. Embora ambos sejam usados para mover e transformar dados, existem algumas diferenças importantes:
Pipeline de Dados: mais abrangente, podendo incluir fluxos contínuos de dados (streaming) e permitir múltiplas transformações ao longo do caminho. Ele pode suportar tanto o modelo ETL quanto ELT (Extract, Load, Transform), dependendo das necessidades do projeto.
ETL: Foca na extração, transformação e carga de dados em um data warehouse. Tradicionalmente, o ETL é um processo executado em lotes, ideal para grandes volumes de dados processados periodicamente.
Pensando em um cenário prático. Se você precisa processar grandes quantidades de dados históricos de vendas uma vez por dia, o ETL pode ser suficiente. Mas se a sua empresa precisa monitorar transações em tempo real para detecção de fraudes, um pipeline de dados em streaming será a escolha ideal.
Características dos Pipelines de Dados Modernos

Os pipelines de dados modernos evoluíram muito nos últimos anos. Hoje, eles precisam ser:
Interoperáveis: Devem integrar-se bem com diferentes fontes e destinos de dados, sejam eles on-premises ou na nuvem.
Escaláveis: Capazes de lidar com grandes volumes de dados e crescer conforme a demanda.
Resilientes: Devem ser capazes de lidar com falhas e continuar o processamento sem perder dados.
Modulares: Devem ser compostos de componentes independentes, facilitando a manutenção e o escalonamento.
Observáveis: Ferramentas de monitoramento como Grafana e Prometheus são essenciais para garantir que o pipeline funcione corretamente.
Ferramentas para Transformação de Dados
A transformação de dados é uma das etapas mais importantes de um pipeline, pois é aqui que os dados são preparados para análises e tomadas de decisão. Algumas das ferramentas mais populares incluem:
Pandas: Muito utilizado para pequenas transformações de dados em Python, ideal para análises exploratórias e prototipagem.
Apache Spark: Um dos frameworks mais utilizados para processamento de grandes volumes de dados. Oferece suporte para processamento em batch e streaming.
dbt (Data Build Tool): Focado em transformação de dados dentro de um data warehouse, utilizando SQL para criar modelos analíticos.
Apache Beam: Um modelo unificado para processamento de dados, que pode ser executado em várias plataformas, como Apache Flink e Google Dataflow.
Ferramentas para Construir Pipelines de Dados: Armazenamento e Cloud Computing

Ao construir pipelines de dados, o armazenamento e a infraestrutura na nuvem desempenham um papel crucial. Algumas ferramentas e serviços populares incluem:
Snowflake e BigQuery: Data warehouses modernos, otimizados para grandes volumes de dados e análises em tempo real, com suporte a ELT.
Amazon S3 e Google Cloud Storage: Usados para armazenar dados brutos e intermediários. São altamente escaláveis e suportam integração com diversas ferramentas de processamento.
Apache Airflow: Uma plataforma de orquestração que permite criar, agendar e monitorar pipelines de dados complexos.
Kubernetes: Facilita o gerenciamento de contêineres, oferecendo escalabilidade e resiliência para pipelines de dados distribuídos.
AWS Glue e Google Dataflow: Serviços gerenciados que simplificam o desenvolvimento de pipelines ETL e de dados em streaming.
Os pipelines de dados são a espinha dorsal da engenharia de dados moderna. Eles permitem a coleta, transformação e entrega de informações de forma escalável e eficiente, possibilitando que empresas tomem decisões baseadas em dados em tempo real. Entender seus componentes, diferenças em relação ao ETL e ferramentas disponíveis é fundamental para qualquer profissional de dados que deseja construir soluções robustas e escaláveis.
Saiba mais:
link: towards data science
link: AWS Big Data Blog
link: Apache Airflow
link: Salesforce – Morden Data Pipeline



